
正所谓“流氓懂科学,谁也挡不住”。如今越来越多的复杂统计数据像潮水般向我们涌来,一批又一批的调查结果,都显得那么铿锵有力,似乎那就是客观事实。统计陷阱被科学流氓们包装的越发完美,一不小心就把我们忽悠了。该怎么办呢?别急,且看死理性派现身说法,帮大家理清真相。

调查问卷你肯定知道,多半还做过。在统计上,问卷调查属于抽样调查。再大规模的抽样调查,都可能存在着意想不到的陷阱。不妨让我们穿越到 1936 年的美国,看一个被许多书本都引用过的实例吧。
1936 年美国总统大选在即,当时一本著名杂志 《文学文摘》 就在读者中做了一次问卷调查,断言共和党的兰登即将以 57% 对 43% 的绝对优势大胜民主党的罗斯福——这可是根据 240 万份调查问卷得到的结果。这么大规模的调查,如同宣告了兰登的胜利,可是,最后的结果却让人大跌眼镜:罗斯福以 62% 的支持率成功连任美国总统。出现了这个戏剧性的丑闻后,《文学文摘》业绩直接掉落为零,最后竟然倒闭了。对于《文学文摘》来说,他们的问题出在哪里呢?
现在看来,《文学文摘》的调查问卷虽然数量庞大,但是样本构成大有问题。首先,最可能看到这个调查的是这个杂志的常客,而他们参加调查的动机各有不同。另外,这个话题更能引发人的兴趣,有些则只是很少的人关心。这都会导致最终参加调查的人是一个有偏的样本。结论可能代表了这些人群,却不能推广到全体。
其次,问卷的回收率只有 24% ,忽略那些没有被回收的问卷就等于是忽略了剩余 760 万人的意见。《文学文摘》杂志社还通过电话调查的方式对自己的读者进行了抽样,但在 1936 年,并不是每一个家庭都能装得起电话——那些订阅杂志、用电话的人家往往都是有钱的人,他们并不能代表全美国的选民意见。最终,这些看起来不算起眼的问题对他们的预测结果产生了巨大影响,事情的发展也走向了完全相反的方向。
如果我们现在做一个调查,看一看在最初恢复高考的三年中进入几所名牌大学就读的学生如今的年收入,你一定会得到一个高得吓人的数字。我敢如此肯定并不是我熟悉他们的社会成就,而是因为我了解调查的缺陷。可以想见,当年的那些大学生虽然有案可查,但能够准确联系调查的却只有一部分较为成功的人了。其中有一些人虽然联系上了,却不一定愿意接受调查。最后,还不能排除一些人受赞许倾向的影响,有意无意地提高报告自己的收入水平。最终,调查员只回收了那些成功人士的数据,而沉默的大多数却被“统计式”地忽视了。
为了让没有直接接触数据的人也能直观地感受到其中的一些信息,人们发明了各种各样漂亮的统计图表。但是就是“客观”的图表里面也存在着各种各样的陷阱。
在制作统计图表时,一个常用的欺骗手法便是改变统计图形的坐标尺度,从而改变了整个图形的陡峭程度。《统计陷阱》一书中就曾举过这样一个例子。下图反映了某年9月27日某时的黄金价格走势。
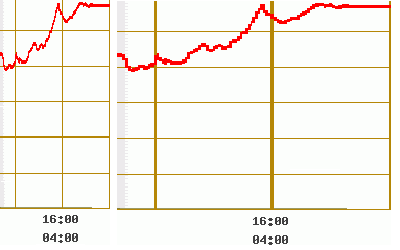
上面两幅图描述的是相同时间段的黄金价格走势,显然,左边的金价急升更容易让人产生激动的心情。右边将左边的图横向拉长了,使得它看起来是在更短的时间内冲上高峰,即使标出了横纵轴的刻度,这两幅图给普通人留下的第一印象也大不一样。
当然,还有比拉伸图表更隐蔽的手法。现在我们手上有一组罗坦提亚和美国的木匠平均周收入,如果做成条形图就像下面那样:
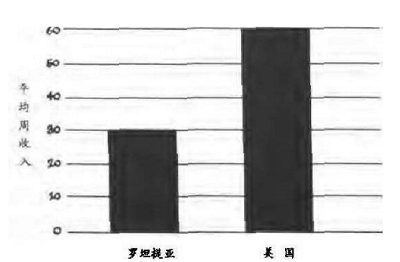
看得出来,美国木匠的平均收入是罗坦提亚木匠的两倍。但通常为了视觉效果,它会被做成更形象的卡通图。这其实却暗中改变了人们对这个统计事实的印象。

美国人的钱袋长、高都是罗坦提亚木匠的两倍,看起来挺忠实于数据的,但是右边钱袋实际占用的面积就是左边的4倍。这幅图像导致的暗示效果其实还没完,因为在生活中钱袋都是立体的,所以每个读者看到这个钱袋的时候会不经意地给它加上一个厚度,这样一来,在有些人眼里这幅图表达的明明是美国木匠的收入是罗坦提亚的8倍——这样的印象完全脱离了原始数据所给出的信息,无疑是一次成功的误导。
上面说了几个很容易让公众迷惑的统计陷阱,那当我们看到各类统计数字时,应该如何判断它是否客观呢?
首先要细心寻找统计中的偏差。比较明显的是在描述上有意识进行的偏差。比如滥用平均数等带来的问题:“我们工厂 3000 人,月平均工资有 5000 块。”看起来比较不错的待遇,实际上可能是一个月薪 100 万的老总加上每个月拿着可怜薪水的上千名工人简单平均起来的结果。同时报道中常常声称的“升高”和“下降”并不一定真的如此。在面对类似“这段时间气温异常升高,热浪持续一周导致城市死亡人数激增至 300 人”这样的标题时,我们往往要小心这里所说的“激增”是否属实。一个一定规模的城市在一周内有 300 人死亡并不算是异常的数字,而热浪实际上是一个没有多少分量的因素。半个世纪以前,纽约市的两份报纸上面刊登的犯罪数量一度达到了令人发指的水平,迫于舆论压力,当时的警察联合会主席不得不有所表示,但是他仅仅采用了一个行动就平息了这场风波——他解雇了两名编辑,因为这场风波是他们在互相竞争着挖掘犯罪事件并搬上台面,导致对民众产生误导。事实上,警察局的统计数据表示这段时间的犯罪事件数量并没有上升。
其次我们要寻找潜伏着的无意识偏差,这种偏差带来的结果往往影响更深远——《文学文摘》就是无意识偏差的受害者。无意识偏差常常会体现在对样本的选取不注意上。一个超市对50名顾客进行了调查,得出了“ 75% 的人声称喜欢喝茶而不是咖啡”的结论,那么我们大可不必去相信这个结论,因为相比起总数来说, 50 个人实在是微不足道的。这家超市也发现了这个问题,接着发出 10000 份调查问卷,最后回收了 2300 份,发现“ 64% 的人声称喜欢喝茶而不是咖啡”,这个结论毫无疑问也不能令人信服。实际上这个调查体现出来的是有 1472 个人更喜欢喝茶,828 个人更喜欢和咖啡,但是还有剩下 7300 个人没有给出答案——这是光看结果分析的读者所无法知道的,所以不能简单地相信一个直接而草率的结论。
最后我们要注意保持对统计图示和统计数据的敏感性。图标会有意无意地通过巧妙设计(比如横纵轴的尺度问题),从而使得这幅图凸显的内容就是作者期望读者能够收到的信息。在观看图表的时候,我们可以试图在脑海中想象出与图像所对应的具体数据,只要图像不是捏造的,那么就能够在一定程度上摆脱视觉上的误导。然而白底黑字的统计数字又怎么会出错呢?捏造的数字当然是错误的。比如当年闹得沸沸扬扬的 87.53%事件 ,但如果报道中提到的被调查人数是 130 人,不知道还会有多少人能发现这个数据不正确?113 个人表示支持的话,那么支持率是 86.92% ,114 个人表示支持的话,那么支持率是 87.69% ——无论如何也得不到 87.53% 的数据,但是这样造假的数据却大大提高了可信度,让人再难发现起谬了。实际上,很多的假数据都利用到了人们天生对“精确的数字”的信任——“在校大学生每日开销大约为 50 元”的说法就不如“在校大学生每日开销为 51.74 元”更显真实。仔细想想,我们每天接触着海量的信息,身边有多少数据是这样以假乱真的呢?
或许对于那些统计学家来说,只有下面这幅图才让人感到一点点的安心吧:

参考资料:
科学松鼠会: 做一次生活科学家
《统计陷阱》 [美] 达莱尔·哈夫
(编辑:彭宣朝)

